之前写SpringBoot项目,每次都要手动去写实体类、dao层啥的,尤其是数据库表字段特别多的时候,特别麻烦。然后很多小伙伴都会用逆向工程来自动生成这些类,省去许多没必要的代码量,但是Mybatis的逆向工程依然需要配置,导逆向工程的jar啊,还有编写generatorConfig.xml文件啊(有兴趣的朋友可以看看这篇)。今天逛gitee的时候,看到了一款可以免去许多配置的idea逆向工程插件,几个步骤简单使用一下
这个插件。
一、下载并安装EasyCode插件
Setting->Plugins。搜索EasyCode插件,并重启Idea编辑器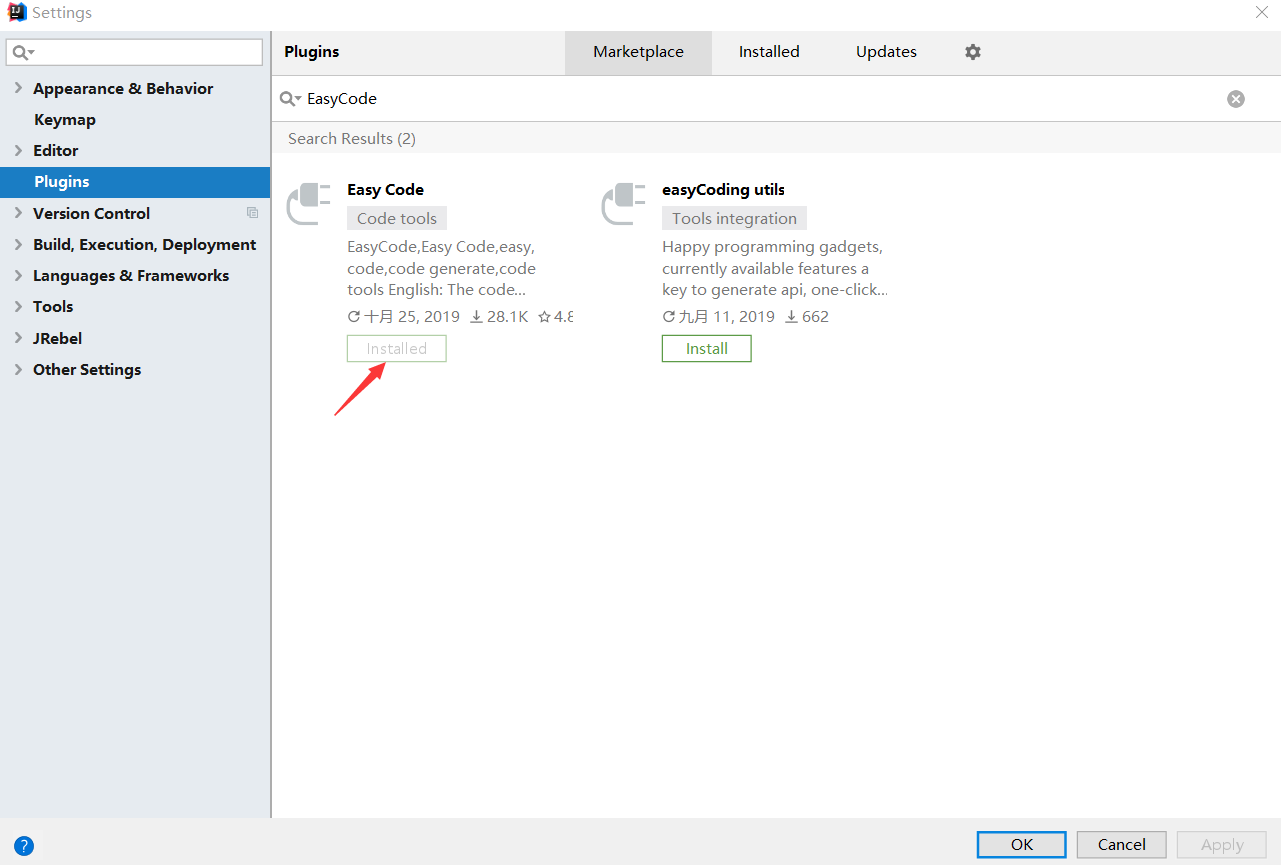
二、配置MYSQL数据源
点击Idea右侧的Database,然后再点一下加号,选择你的数据库类型,我这里选择的是MySQL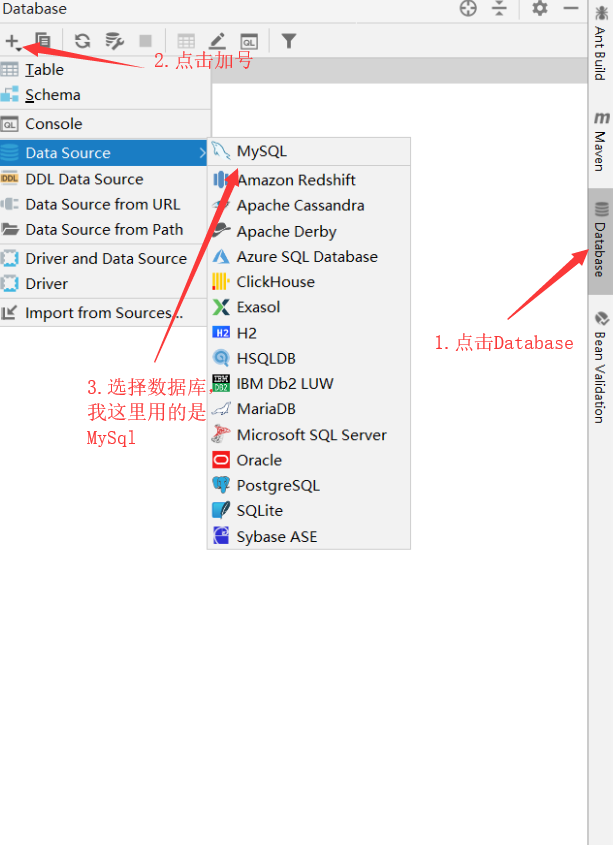
三、配置连接参数
配置好自己的数据库连接参数后,点击Apply,然后再点击Schemas选择使用哪个数据库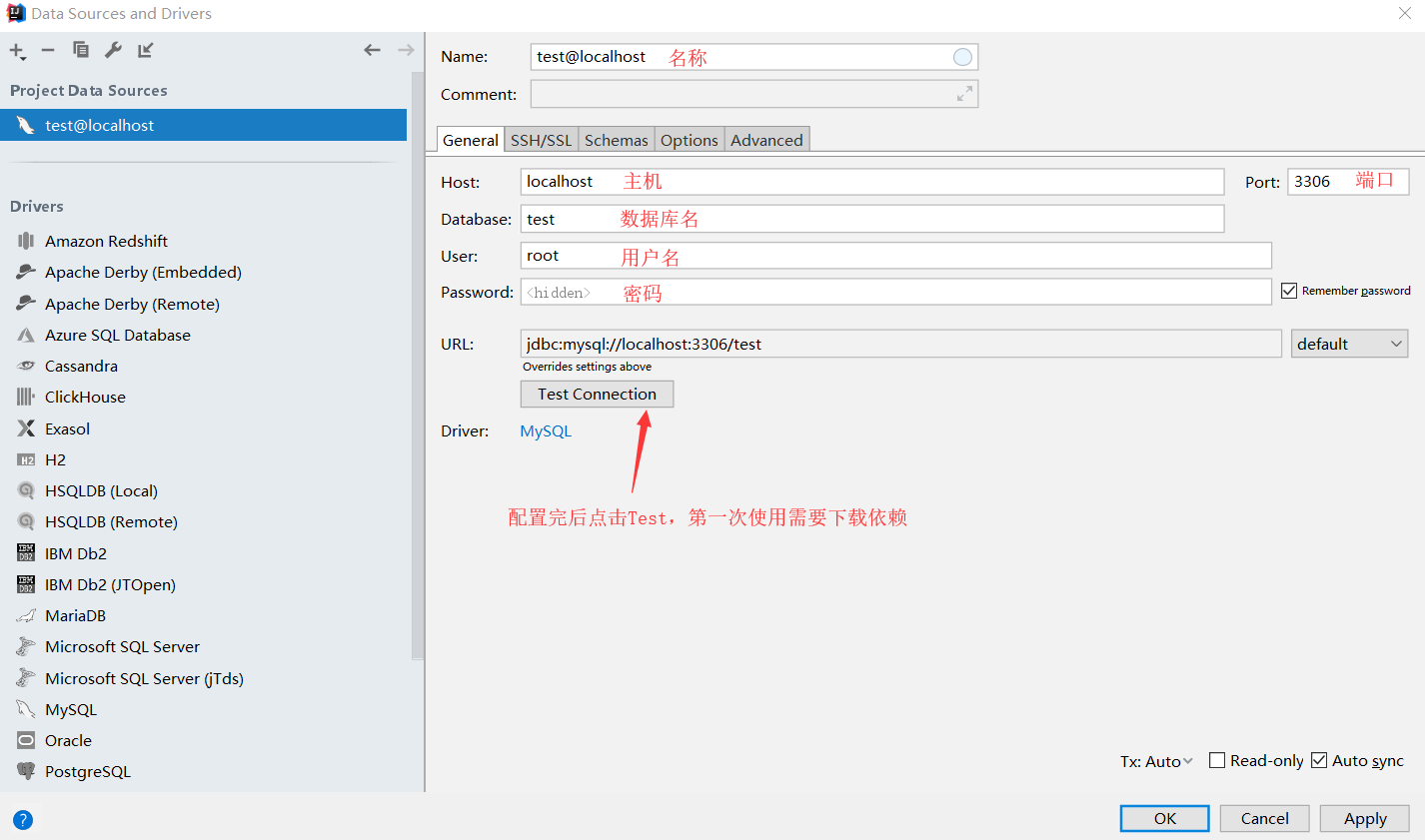
四、生成代码
如图,点击Generate Code
这里选择项目模块,还有需要生成的代码
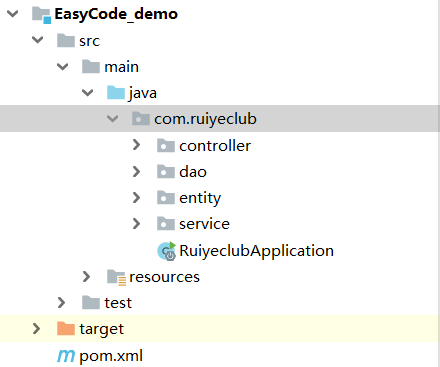
生成后的目录就这个样子,里面还写好了单表的CRUD操作